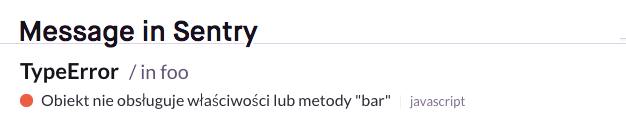According to Stack Overflow’s Developer Survey 2019, Go is the third most wanted language to learn, as well as the third-best paid technology in the field. It is not a surprise, as it is one of the languages used for writing critical parts of a lot of large systems. The language design and syntax are simple, but developing in Go is far from easy.
Some of the features Go provides:
- recovering from panic
- reporting errors
- recording breadcrumbs
- logging messages
- extracting stack traces from errors and panics
- errors filtering
- integration with various HTTP libraries
- async/sync transports
- serverless support
- extracting request/os/device data
- thread-safe data separation
We decided to spend some time on writing a new, unified SDK, that supports all recent versions of the language, utilizes its features, and gives developers the most helpful hints possible for where and why the error might happen.
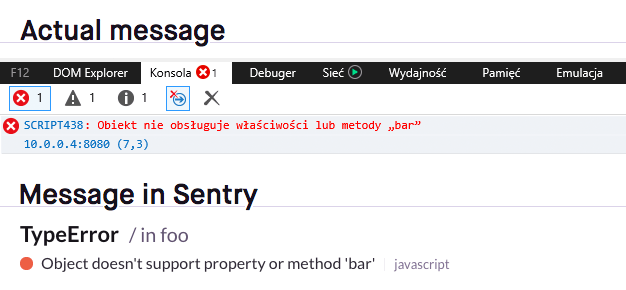
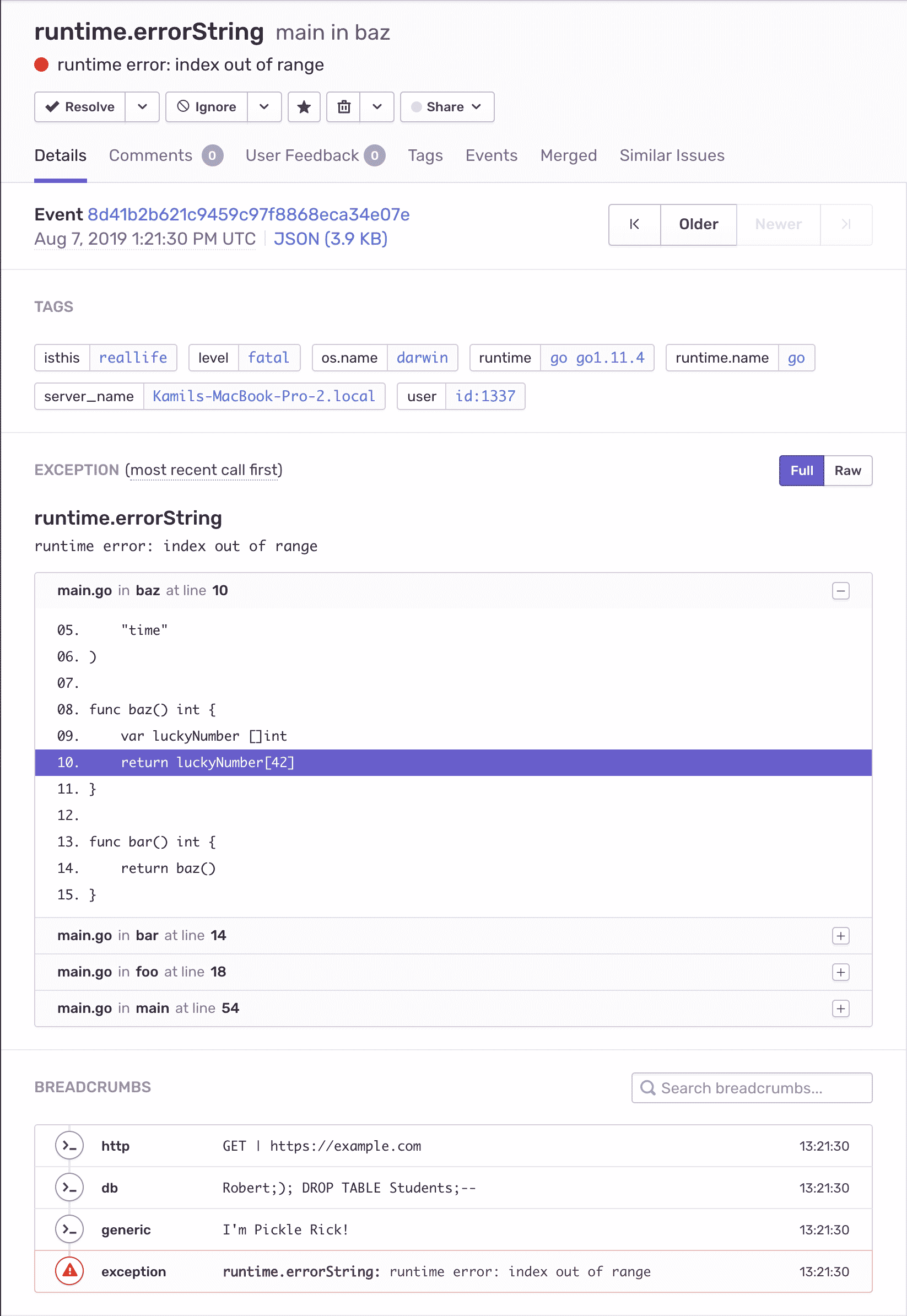
Here’s what a Go exception looks like in Sentry.
Getting Started
sentry-go provides a Sentry client implementation, which is in-line with our Unified API guidelines and is intended to replace the old raven-go package. The SDK supports Go Modules by design; therefore, when installed, it picks up the latest version of the SDK and stores it inside the go.mod file. Non-major changes should never break your builds.
$ go get github.com/getsentry/sentry-go
The only thing you need to call to initialize the SDK is sentry.Init with a proper DSN obtained from your Sentry account.
sentry.Init(sentry.ClientOptions{
Dsn: "YOUR_PUBLIC_DSN",
})
Once configured, you can start using any publicly available API, and it’ll track your data and report captured errors.
Now, let’s go through some real-world use-cases, as this sounds way more interesting.
Capturing Panics
Sentry provides two ways of recovering from panics: RecoverWithContext(), which can pass Context around, and Recover(), which does not pass Context around. Unless you are moving data around or using some cancel/timeout functionalities, Recover() is the way to go.
Below, we call a function that we know breaks by fetching a number from a slice that is definitely not there. How can we make sure that exception reports to Sentry? With Recover(), that’s how.
func bar() int {
var luckyNumber []int
return luckyNumber[42]
}
func foo() int {
return bar()
}
func main() {
// Initialize Sentry here
defer sentry.Flush(time.Second * 5)
defer sentry.Recover()
foo()
}
By default, sentry-go uses asynchronous transport, which requires an explicit signal for event delivery finish using the sentry.Flush method. Otherwise, the program doesn’t wait for the async HTTP calls to return a response and exits the process immediately when reaching the end of the main function. sentry.Flush isn’t required inside a running goroutine or if you would use HTTPSyncTransport, which you can read about in our docs.
Capturing Errors
Reporting errors is even easier, because in Go, “error is just a value.”
var ErrMissingLuckyNumber = errors.New("Missing lucky number, sorry")
var luckyNumbers = map[string]int{
"pickle": 42,
}
func getLuckyNumber(key string) (int, error) {
if val, ok := luckyNumbers[key]; ok {
return val, nil
} else {
return 0, ErrMissingLuckyNumber
}
}
func main() {
// Initialize Sentry here
number, err := getLuckyNumber("pickle")
if err != nil {
sentry.CaptureException(err)
sentry.Flush(time.Second * 5)
} else {
fmt.Println("Your lucky number is:", number)
}
}
The same goes for simple messages.
// same getLuckyNumber implementation
func main() {
// Initialize Sentry here
if _, err := getLuckyNumber("pickle"); err != nil {
sentry.CaptureMessage("Lucky number wasn't there, but let just log it as a message and proceed")
}
// the rest of your program
}
Breadcrumbs
Breadcrumbs are a small message-hints that help track what went wrong during program execution, including some HTTP call, a DB query, data parsing, you name it.
Let’s simulate the scenario:
func performHTTPRequest(url string) string {
sentry.AddBreadcrumb(&sentry.Breadcrumb{
Message: fmt.Sprintf("GET | %s", url),
Category: "http",
})
// performing HTTP request
return "I'm Pickle Rick!"
}
func performDBQuery(query string) string {
sentry.AddBreadcrumb(&sentry.Breadcrumb{
Message: query,
Category: "db",
})
// performing DB query
return "https://example/com"
}
func processData(data string) error {
return errors.New("something broke, sorry")
}
func main() {
// Initialize Sentry here
url := performDBQuery("Robert;); DROP TABLE Students;--")
if data := performHTTPRequest(url); data != "" {
sentry.AddBreadcrumb(&sentry.Breadcrumb{
Message: data,
})
if err := processData(data); err != nil {
sentry.CaptureException(err)
}
}
}
With this setup, your error has three beautiful breadcrumbs that look exactly like the on the screenshot in the very top of this blog post.
Contextual Data
Now and then, it’s useful to correlate some additional data with a captured panic or error. To do this, we also provide two methods: one that stores the data in the global Scope object and attaches it to every following event, and one that does this only for events captured in its callback function.
func main() {
// This data will be attached to every event sent to Sentry
sentry.ConfigureScope(func(scope *sentry.Scope) {
scope.SetTag("isthis", "reallife")
scope.SetExtra("oristhis", "justfantasy")
scope.SetUser(sentry.User{
ID: "1337",
})
})
// For example this one
sentry.CaptureMessage("hey there!")
// However, this data will be only attached to the events that are captured inside it's callback
// it'll contain global data configure above and its own "internal" one
sentry.WithScope(func(scope *sentry.Scope) {
scope.SetExtra("caught", "inalandslide")
sentry.CaptureMessage("no escape from reality!")
})
// And this one
sentry.CaptureMessage("hey there too!")
}
Goroutines
Capturing panics and errors, breadcrumbs, and contextual data are all well and good, but what about goroutines? No worries — we’ve got you covered.
The only thing you have to remember is that, in threaded environments, you have to take care of the data that’s living inside it, be it Scope instance or the Client you configure with sentry.Init. Thankfully, Hub keeps track of corresponding Scope and Client, allowing them to communicate with each other.
One of the methods that Hub uses is Clone, which (as you can guess) clones the top-most scope on the stack and reassigns the pre-configured client. Clone enables calls all major public APIs, but in a completely separated manner, where you don’t have to worry about overriding your scope data or race-conditions.
Here’s how:
func main() {
// Initialize Sentry here
go func() {
localHub := sentry.CurrentHub().Clone()
localHub.ConfigureScope(func(scope *sentry.Scope) {
scope.SetTag("secretTag", "go#1")
})
localHub.CaptureMessage("Hello from Goroutine! #1")
}()
go func() {
localHub := sentry.CurrentHub().Clone()
localHub.ConfigureScope(func(scope *sentry.Scope) {
scope.SetTag("secretTag", "go#2")
})
localHub.CaptureMessage("Hello from Goroutine! #2")
}()
}
Hub and Clone make sure that the data belongs where it needs to and that captured events are enhanced in a correct way.
HTTP Packages
Our Go SDK provides integration with a variety of HTTP libraries: net/HTTP, Echo, FastHTTP, Iris, Gin, Martini, Negroni, and the list is still growing. Every integration automatically captures panics for your request handlers and exposes Request object for your disposal.
Let’s see how one may use it with one of the most popular packages, gin:
package main
import (
"fmt"
"net/http"
"github.com/getsentry/sentry-go"
sentrygin "github.com/getsentry/sentry-go/gin"
"github.com/gin-gonic/gin"
)
func main() {
sentry.Init(sentry.ClientOptions{
Dsn: "YOUR_PUBLIC_DSN",
AttachStacktrace: true,
})
app := gin.Default()
// Gin has its own Panic handle, which sends 500 to the user
// therefore after catching and reporting it to Sentry, we hand it over further
app.Use(sentrygin.New(sentrygin.Options{
Repanic: true,
}))
// Add some contextual data, that can be extracted from the request
app.Use(func(ctx *gin.Context) {
if hub := sentrygin.GetHubFromContext(ctx); hub != nil {
hub.Scope().SetTag("someRandomTag", "maybeYouNeedIt")
}
ctx.Next()
})
app.GET("/", func(ctx *gin.Context) {
// Use a Hub that is stored on the request's context (added by Sentry's integration)
// And capture a message that will inform us about some unusual behavior,
// despite request not panicking
if hub := sentrygin.GetHubFromContext(ctx); hub != nil {
hub.WithScope(func(scope *sentry.Scope) {
scope.SetExtra("unwantedQuery", "someQueryDataMaybe")
hub.CaptureMessage("User provided unwanted query string, but we recovered just fine")
})
}
ctx.Status(http.StatusOK)
})
app.GET("/foo", func(ctx *gin.Context) {
// sentrygin handler will catch it just fine, and because we attached "someRandomTag"
// in the middleware before, it will be sent through as well
panic("y tho")
})
_ = app.Run(":3000")
}
Note the AttachStacktrace client option that ensures, despite panic throwing just a string our way, we can extract the stack trace and add more context to the Sentry event report page.
What’s next?
Right now sentry-go is in it’s “pre-v1” stage. The SDK has a stable API that we test in the wild, but we look for ways to make it better (including listening to feedback). We already have some ideas that you can track in our GitHub issues page.
If you’d like to request a feature, help with implementing a feature, or have a better way of solving problems, feel free to let us know, and we’ll make sure that your voice is heard!
]]>